
Chi tiết về Intel Xe HPC Architecture, chức năng kép tăng tốc tính toán và tăng tốc cloud-gaming.
Kiến trúc Xe HPC (tính toán hiệu suất cao) của Intel cung cấp sức mạnh cho thiết bị tính toán vector mạnh nhất của công ty cho đến nay, có tên mã là "Ponte Vecchio." Bộ xử lý được thiết kế cho các ứng dụng tính toán HPC và AI lớn, nhưng cũng có đồ họa raster và phần cứng raytracing thời gian thực, mang lại cho nó khả năng sử dụng kép như một GPU chơi game trên đám mây.
Bài viết về kiến trúc Xe HPG của chúng tôi đề cập đến những kiến thức cơ bản về cách Intel sử dụng GPU rời cho khách hàng của mình. Kiến trúc Xe HPC vừa được tăng cường và mở rộng. Xe-core, đơn vị con cơ bản không thể phân chia, của kiến trúc Xe HPC khác với Xe HPG. Trong khi các lõi Xe HPG chứa 16 vector engines 256 bit cùng với 16 matrix engine 1024 bit matrix engines; các lõi Xe HPC có 8 vector engines 512-bit, bên cạnh 8 matrix engine 4096-bit. Nó cũng có băng thông tải / lưu trữ cao hơn và bộ nhớ đệm L1 512 KB lớn hơn.



Đơn vị vector lõi của Xe HPC được thiết kế đầy đủ hiệu suất FP64 , 256 ops trên mỗi xung nhịp, giống với thông lượng FP32 của nó. Nó cũng cung cấp 512 ops trên mỗi xung nhịp FP16. Mặt khác, đơn vị ma trận đóng gói 2.048 TF32 ops / chu kỳ, lên đến 4.096 FP16 và BFloat16 ops / chu kỳ, và 8.192 INT8 ops / chu kỳ.
Mọi thứ trở nên thú vị khi chúng tôi mở rộng quy mô từ đây. Xe HPC Slice là một nhóm gồm 16 lõi Xe HPC, cùng với 16 dedicated Raytracing Units có khả năng giống như các đơn vị trên Xe HPG (tính toán truyền tia, giao điểm hộp giới hạn và giao điểm tam giác). Xe HPC Slice tích lũy có 8 MB bộ nhớ đệm L1 riêng.
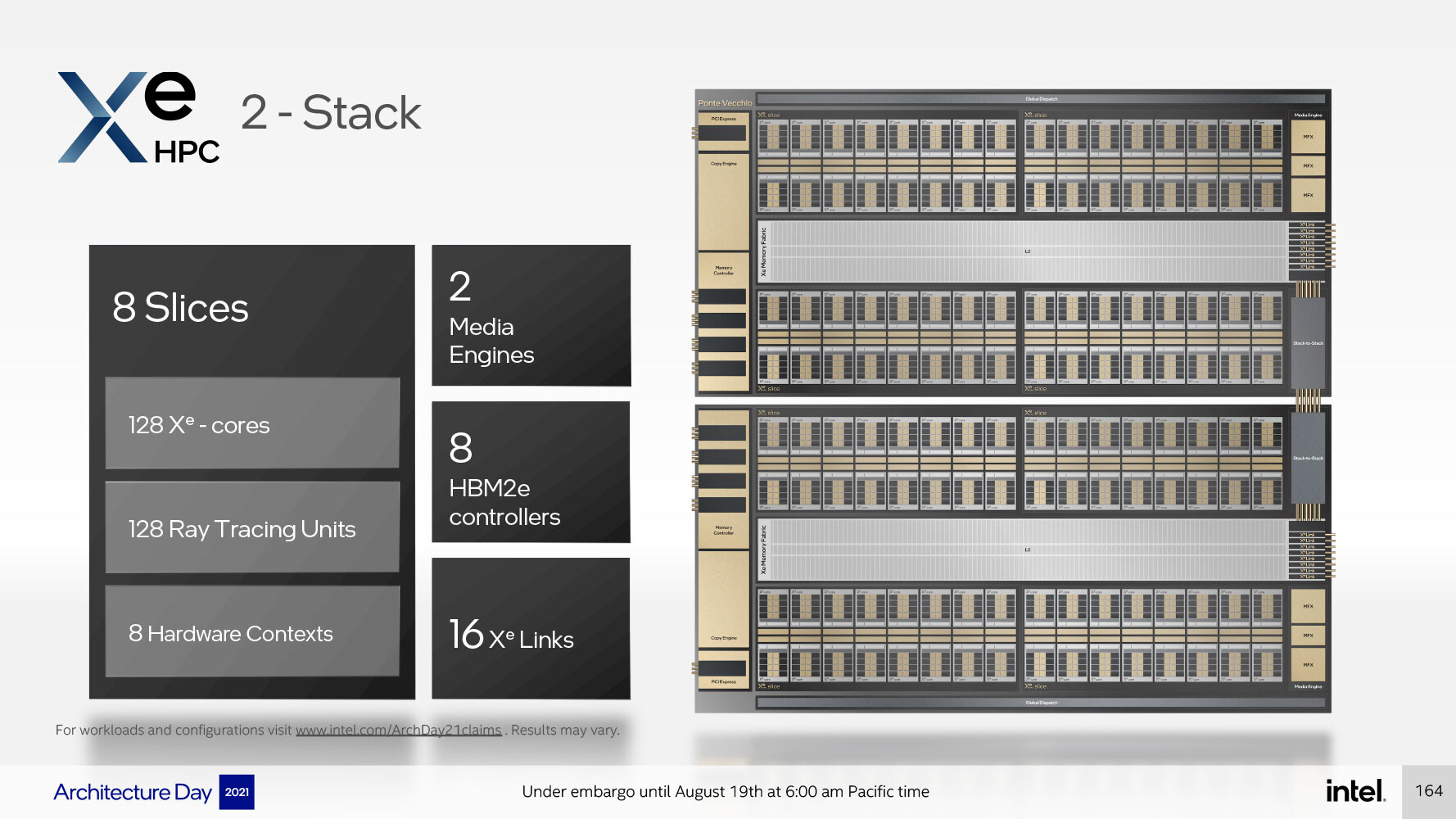


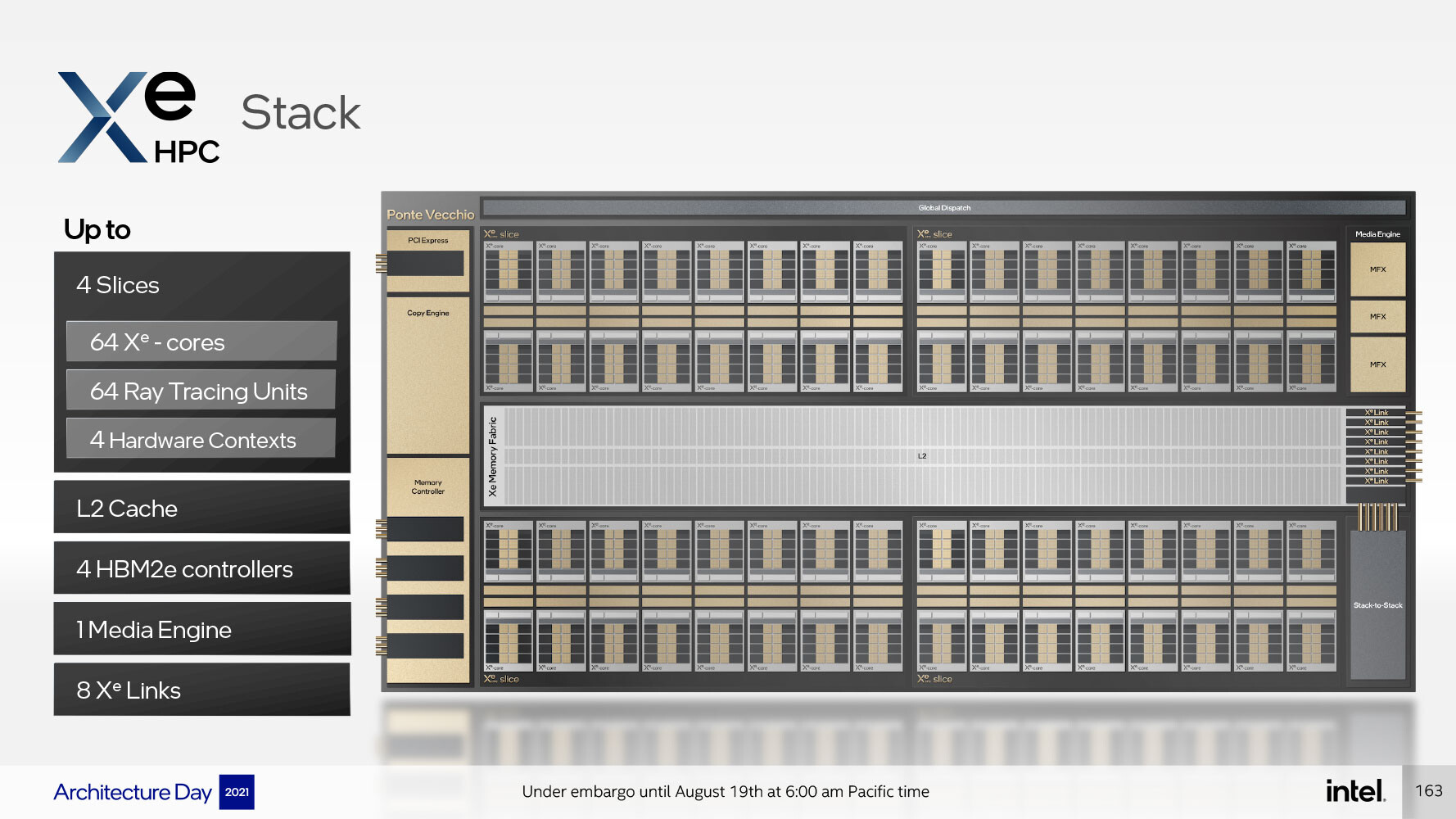
Một ô tính toán Xe HPC, hay Xe HPC Stack, chứa 4 Xe HPC Slices, 64 lõi Xe HPC, 64 Raytracing Units, 4 hardware contexts, chia sẻ một bộ nhớ đệm L2 lớn 144 MB. Các thành phần có thêm bao gồm giao diện PCI-Express 5.0 x16, giao diện bộ nhớ HBM2E rộng 4096 bit, media-acceleration engine với chức năng phần cứng để tăng tốc giải mã (và có thể mã hóa) các định dạng video phổ biến và Xe Link, một kết nối được thiết kế để giao tiếp với tối đa 8 ngăn xếp kép Xe HPC khác, với tổng số lên đến 16 stacks. Mỗi stacks kép sử dụng kết nối low-latency stack-to-stack. Do đó, mỗi dual-stack kết thúc lên đến 128 lõi Xe HPC, 128 Đơn vị Raytracing, hai công cụ đa phương tiện và giao diện HBM2E rộng 8192-bit. Dual-stack là một nhóm có liên quan ở đây, vì bộ xử lý "Ponte Vecchio" có hai ô tính toán (hai ngăn xếp Xe HPG) và tám ngăn xếp bộ nhớ HBM2E.




Điều quan trọng cần lưu ý ở đây là Xe HPC Slices nằm trong các khuôn chuyên dụng được gọi là các ô tính toán được chế tạo từ nút N5 5 nm của TSMC, trong khi phần còn lại của phần cứng nằm trên một khuôn đế được xây dựng trên nút Intel 7 (10 nm Enhanced SuperFin). Hai khuôn được Foveros xếp chồng lên nhau với các vết sưng 36 micron.
Gạch Xe Link là một miếng silicon riêng biệt chuyên dùng để kết nối mạng với các gói hàng lân cận. Khuôn này được xây dựng trên nút TSMC 7 nm, và chủ yếu bao gồm các thành phần SerDes (bộ giải tuần tự).




Mỗi OAM "Ponte Vecchio" với hai ngăn xếp Xe HPC (một MCM), băng thông bộ nhớ kết hợp trên 5 TB / s và băng thông kết nối Xe Link trên 2 TB / s. Một Hệ thống con "Ponte Vecchio" x4 chứa bốn OAM như vậy và được thiết kế cho một nút 1U với hai bộ xử lý Xeon "Sapphire Rapids".
Bốn gói "Ponte Vecchio" và hai "Sapphire Rapids" đều được làm mát bằng chất lỏng. Phần cứng chỉ là một phần của câu chuyện, Intel đang đầu tư đáng kể vào OneAPI, một môi trường lập trình chung cho cả CPU và GPU.



Nguồn: https://www.techpowerup.com/285769/intel-xe-hpc-architecture-detailed-has-dual-use-as-compute-and-cloud-gaming-accelerator
Tags:
Công nghệ